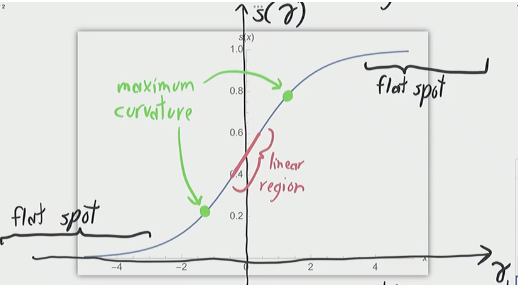
Problem: when unit output s is close to 0 or 1 for most training points, is going to be very small making the gradient descent very slow and not efficient. Unit is Stuck | Slow Training. (We don’t want the data to be in the flat spot). Also, the middle part (non-flat) part is kinda like a linear region. We want neural networks to have non-linear activation functions.
Solution: Replace Sigmoids with Rectified Linear Units (ReLUs)
Rectified Linear Units (ReLUs)
def relu(x):
return np.maximum(0, x)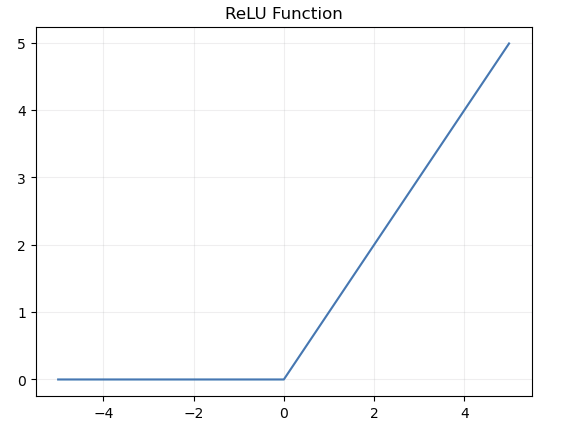
Sub-gradient at x = 0 is not a very big problem.
- In ReLU, Exploding Gradient can be a problem in Deep Neural Network.
- Although it’s mostly linear, in practice, it gives enough non-linearity.
- Most Neural Network today use ReLU Function as Hidden layers.
- ReLUs can get stuck too just like sigmoid functions; but it is rare in practice.
Output Units: chosen to fit the application unlike the hidden layers.
- Regression: Linear regression (Last Layers)
- Classification: Sigmoid (2 class) | Softmax (multi-classes)
Output Units
Regression
The activation function is the identity function. Usually trained with squared error loss. So, it is equivalent to doing least squares linear regression on learned features (hidden units). Loss function: Squared Error Loss
Binary Classification (Sigmoid)
Given vector h of unit values in the last hidden layer, output layer computes pre-activation value , and the applies sigmoid activation function to obtain the prediction .
Loss function: Logistic Loss | Fixes the vanishing gradients at output (because of the shape of logistic loss).
K-class classification (Softmax)
- be a vector of labels for training point x.
- Choose training labels so that
- One-hot encoding
Given hidden layer
houtput layer computes pre-activation value and applies softmax activation to obtain prediction , where
Loss function: cross-entropy loss | Fixes the vanishing gradient problem at the output.
Different in a way that the are dependent on each other if you compare it to the prediction from sigmoid for example.
| output + loss | linear + squared error | sigmoid + logistic loss | softmax + cross entropy loss |
|---|---|---|---|
| , | ; | ; | ; |
| assuming |