Optimization Problem
Find
wthat minimizes:where is the weight without the bias term or bias term 0.
- penalization promotes shrinkage of the weights. i.e. it will encourage our solutions to have smaller weights.
- Also makes the least squares problems to always have a unique minimum solution because of the term — making the matrix to be Positive Definite instead of just Positive Semidefinite.
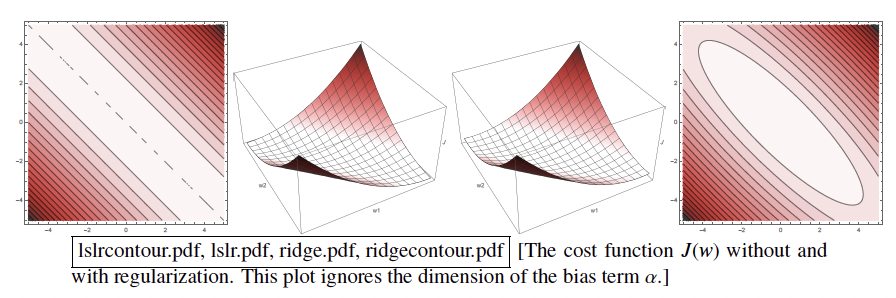
Left figure: ill-pose, many minima. Right figure: well-pose, one unique minima.
regularization reduces overfitting by reducing the variance while increasing the bias. In general, we don’t like big weights if the data and label are relatively smaller.
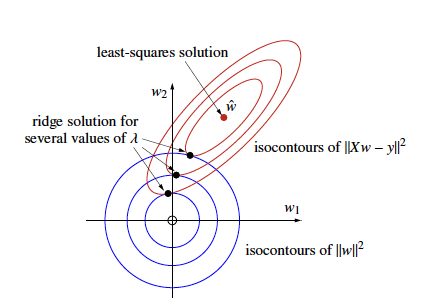
The Ridge Regression solutions lie at the tangent between the red isocontour and the blue isocontour. Notice how higher would pull the solution towards the minimum.
If we were to solve the optimization problem:
The optimal solution would be:
Note that is always Positive Definite and thus invertible - leading to a unique solution. is an identity matrix with the bottom right element being 0 (due to the fact that we don’t penalize the bias term).
Connection of Ridge Regression and Variance
Assume that the true data model is defined as , where e is noise from a Normal Distribution. Then, the variance of the Ridge Regression at a test (arbitrary) point is:
As goes to , variance approaches 0, but the bias increases. In practice, we need to tune the by cross-validation.
Important Note: Features should be normalized so that the weights get penalized in the same amount, and the features will have same variance.
An Alternative way to achieve is this to use a different diagonal matrix instead of , which will weight dissimilar amount to different features.
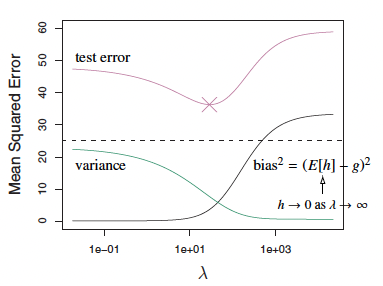
Bias Squared vs Variance as lambda increases.
Warning