Linear Regression and Logistic Regression are two different decision making algorithms.
Linear Regression:
-
produces a continuous output that can take any real value.
-
Linear Regression Equation:
-
Linear regression uses Mean Squared Error (MSE):
Logistic Regression:
- produces a probability (between 0 and 1) which is then used for classification.
- Logistic Regression Equation - uses
sigmoid function. - Logistic Regression uses “Log Loss”.
In GDA, we were regressing over the posterior probability.
- Choose Form of Regression Function h(x; w) with parameters w. (h = hypothesis)
- Choose a Cost function (objective function) to optimize
- Usually based on a Loss Function.
- Empirical Risk (based on the data we have)= Expected Loss (Risk) on data.
- Usually based on a Loss Function.
Some Regression Functions:
- Linear:
- Polynomial
- Logistic: ;
Some Loss Functions:
Let be the prediction given by ; be the true label.
- - squared error - makes it easier to compute.
- - absolute error - not sensitive to outliers. Harder to optimize.
- - Logistic loss, a.k.a cross-entropy. IMPORTANjT* -
Observations
- Squared Error is smooth quadratic and convex - meaning it has a closed form solution. Just set gradient = 0 for minimum.
- Logistic Loss is also smooth but non-quadratic and non-linear - meaning the function is still convex (a single global minimum) but need numerical method to find the optimum.
Some Cost functions to Minimize:
- — mean loss (empirical risk). Note that does not matter in optimization.
- — if you trust your error. Data is robust.
- — weighted sum.
- cost_1 or cost_2 or cost_3 + — penalized / regularization.
- cost_1 or cost_2 or cost_3 + — penalized / regularization.
Important Notation
- Loss function = a “measure” for each data point.
- Cost function = a “measure” for all data point.
Some famous regression methods:
- Least Square Linear Regression → Linear Regression Function + Square Error Loss function + Mean Loss.
- Weighted Least Square Regression
- Ridge Regression:
- LASSO:
- Logistic Regression:
- Least Absolute Deviations:
- Chebyshev Criterion:
- 1 to 4 → Quadratic cost: minimize with calculus.
- 4 → Quadratic Program
- 5 → Convex Cost; minimize with gradient descent.
- 6, 7 → Linear Program.
[Least Square] Linear Regression (Gauss, 1801)
Linear Regression Function + Squared Loss Function + Cost Function = Mean Loss.
Goal of Least Square Linear Regresssion
Find that minimizes . is a bias term.
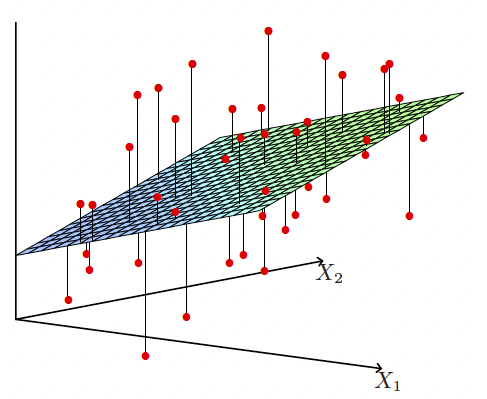
The cost function that we use in linear regression is the sum of squares of errors.
Design Matrix Convention
Design matrix is a
nxdmatrix of sample points and y is anvector of scalar labels.where . The columns are features and the rows are sample points. Typically,
n > dif we have enough sample points.
Fictitious Dimension
Rewrite as
Thus, we will use and . The linear regression problem with bias term can now be rewritten as:
Interpretation: find w that minimizes the squared error
This is a basic Least Squares problem.
Note: In this case, there’s always a solution.
- If X has full column rank ⇒ is PD ⇒ (the features are not dependent) ⇒ unique solution.
- Under-constrained ⇒ is PSD ⇒ multiple solutions.
- Over-constrained ⇒ projection (closest in norm solution). (Not in our case because is PSD.)
We use a linear solver to find .
If exists → X is full-column rank → pseudoinverse of X = = .
Discussion 6 CS 189 for more.
Now, let’s go back to the original problem of predicting the y values. Suppose we have already calculated the weights w, then the projected y values onto the hyperplane with minimum squared error will be:
is also known as H (the hat matrix) since it puts the hat on the y. If you look carefully, you can also see that this is also just a projection of data onto the column space of X.
If , there is no training error since it means all the training points lie on a hyperplane.
Advantages of Linear Regression
- Easy to compute; linear system.
- Unique, Stable Solution unless the system is underconstrained.
Disadvantages of Linear Regression
- Very sensitive to outliers. (because of square errors).
- Fails if is singular but easily fixable.
Least Squares Polynomial Regression
Kernel Trick
The idea here is to life the dataset into higher dimensions so that we could do some regression algorithm on the lifted dataset with linear decision boundary. Lifting data into higher dimensions makes it easier to separate (or fit) with a linear model because, in the original space, the relationship is non-linear.
Replace each with with all terms of degree
Example: ]
But, we need to be cautious since it is very easy to overfit. (too many parameters). A large amount of data can tame the high degree polynomials oscillation. Extrapolation is harder than interpolation.
Weighted Least Squares Regression
Linear Regression Function + Squared Loss Function + Weighted Cost Function.
Assign each sample points a weight (this comes from domain knowledge). Greater means focus more on the same i to minimize .
Weighted Least Squares can be formulated as:
Normal Equations / Solve by finding the gradient (the same).