- Principal Component Analysis is an Unsupervised Learning i.e. we have sample points, but we don’t have labels.
- Therefore, no classes, no regressions, since there’s no
yvalues. Nothing to predict. - What we want to do is Discover some sort of underlying structure in the data.
Popular Techniques of unsupervised learning
- Clustering: Partition data into groups of similar / nearby points.
- Dimensionality reduction: Data often lies near a low dimensional subspace (or manifold) in feature space. Think about matrix low-rank approximation (SVD).
- Density Estimation: Fit a continuous distribution to discrete data.
Principal Component Analysis (PCA) Karl Pearson, 1901
Principal Component Analysis lies under
Dimensionality Reduction.
Given sample points in , find k directions that capture most of the variation.
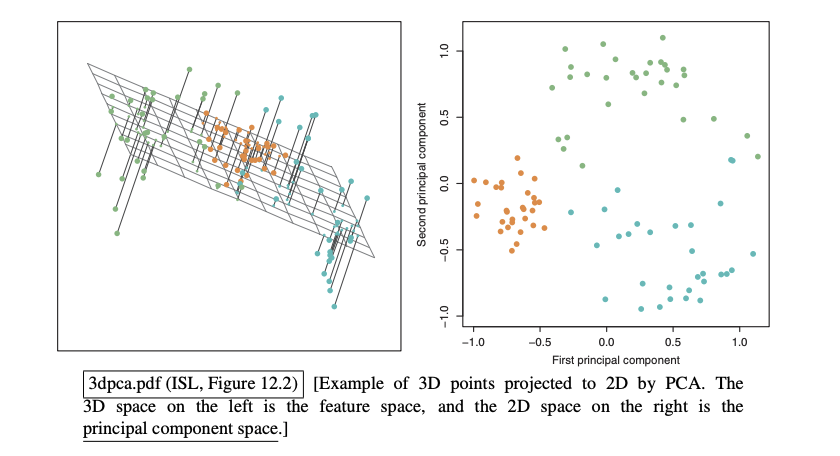
Left is the Feature Space and Right is the Principal Component Space
Example of PCA on hand-written digits (28 x 28) grayscale bitmaps.
One image = 784 dimensional vector → PCA → 2 dimensional vector

As we can see here, the two dimensions may not be enough to capture all the information | the two dimensions may not be enough to maximize the projected data point variance.
Why do we do PCA?
- Reducing number of dimensions makes some computations cheaper. (e.g. regression).
- Identify and remove irrelevant dimensions to reduce overfitting in learning algorithms. Subset selection; but the features are not axes-aligned. i.e. the new features are not the original features. PCA “combine” several input features into one or more orthogonal “new” features known as principal components.
- Find a small basis for representing variations in complex things (faces, genes).
- Let
Xben x ddesign matrix. No fictitious dimension. - Center the
Xand also call itX. So, Find the average across rows, which gives you the mean of each feature. - Let
wbe a unit vector and be the projected data point. The Orthogonal projection of pointxonto vectorwis - If
wis not unit vector, then - The idea is to pick the best
win the sense thatwvector captures the original data the most. - Given orthonormal directions . is the linear combinations of vectors .
- The are not necessarily in the feature space since they’re principal components. Often we just want the
kprincipal coordinates in principal component space (just the coefficient; not the entire vector). - We can compute these principal component directions from eigenvalues of which are PSD matrices.
- The eigenvalues of are all 0. Sort them in the order of .
- Let be the corresponding orthogonal
uniteigenvectors. These are the Principal components.
There are Three ways to derive PCA:
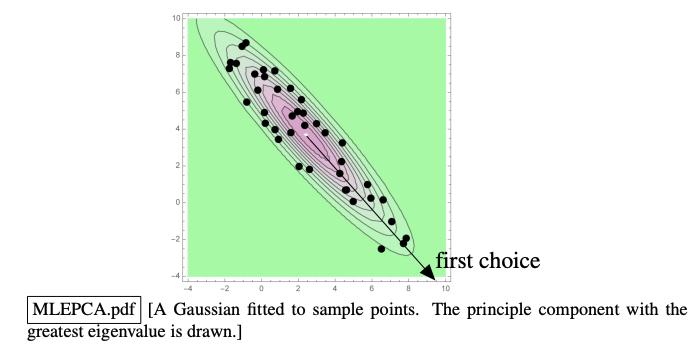
1. Fit a Gaussian to data with maximum likelihood estimation.
- Choose
kGaussian axes of greatest variance. - Recall that MLE estimates a covariance matrix .
2. Find direction w that maximizes sample variance of the projected data.
- Recall Rayleigh Quotient
- The variance of the projected vectors is
- Therefore, Variance is
- is a Positive Semidefinite matrix, and therefore, we can apply Rayleigh Quotient.
- Thus, to maximize the Variance of the projected data points is the same as:
- From Rayleigh Quotient, the optimal solution for this optimization problem(maximize) is
- The optimal direction www is the eigenvector corresponding to the largest eigenvalue of .
- If is the largest eigenvalue of , then the maximum variance will be .
- Therefore, eigenvector corresponding to the largest eigenvalue is the first principal component.
- If we constrain
wto be orthogonal to , we get the second principal component . - Alternatively, using SVD, this corresponds to subtracting (rank-1 approximation) from the original matrix , and applying the same procedure on the residual matrix.
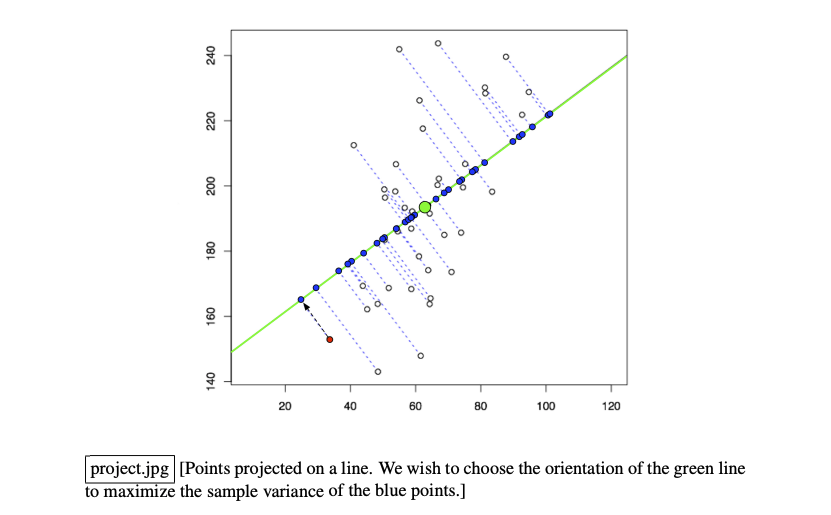
The blue dots are the projected points and we want to maximize the variance of them.
3. Find direction w that minimizes mean squared projection distance
- Similar to Least Square, they both minimize the mean squared distance.
- In Least Square, we measure the distance in
ydirection. - In PCA, we measure the distance from training point to the subspace (hyperplane), perpendicular distance.
- Find
wthat minimizes - This is the same as maximizing the latter term, which is the same as maximizing
n x the variance of the project points (from part 2). - Minimizing the mean squared projection distance = Maximizing the variance of the projected data points.
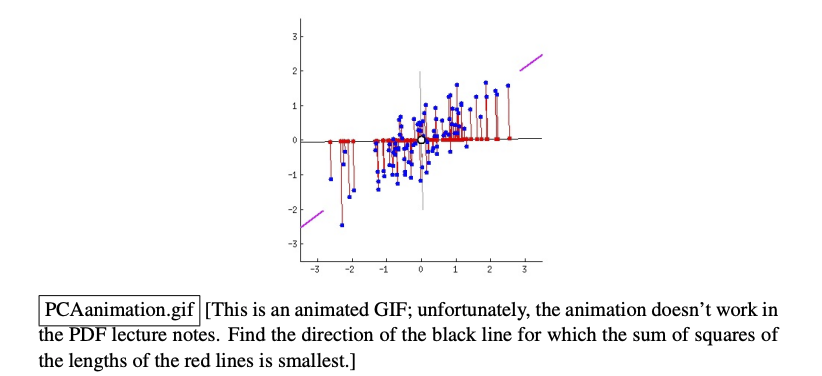
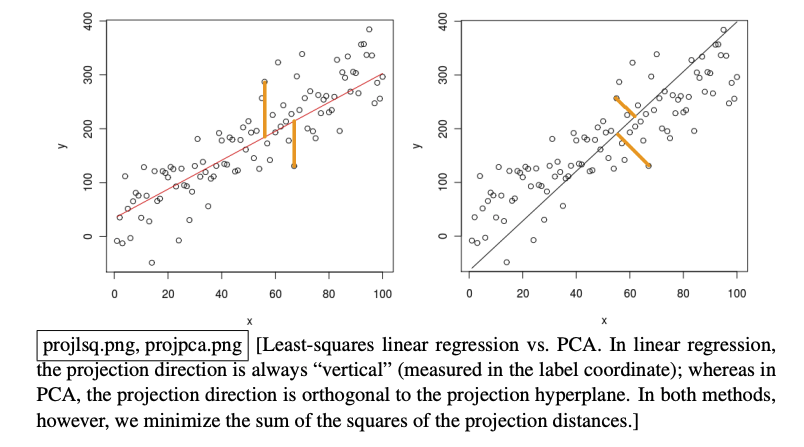
Least Squares Vs Principal Component Analysis Distances
PCA Algorithm:
# center matrix X
mean = np.mean(X, axis=0)
X_centered = X - mean
# normalize X (Optional: units of measurement different?)
# yes: normalize
# no : usually no need to normalize
std = np.std(X_centered, axis=0)
X_centered = X_centered / std
# compute unit eigenvectors and eigenvalues of X^TX.
cov_matrix = X_centered.T @ X_centered / (X_centered.shape[0])
eigvals, eigvecs = np.linalg.eigh(cov_matrix)
# Sort eigenvalues (and corresponding eigenvectors) in descending order
# note: 189 uses the reversed of the following order (ascending order)
sorted_indices = np.argsort(eigvals)[::-1]
eigvals = eigvals[sorted_indices]
eigvecs = eigvecs[:, sorted_indices]
# Choose k. (Optional: use eigenvalues to gauge the optimal k)
k = 3
# For the best k-dimensional subspace, pick eigenvectors
top_k_eigvecs = eigvecs[:, :k] # (d, k)
# compute the k principle coordinates x.v_i of each training / test point.
X_pca = X_centered @ top_k_eigvecs # (n, k)
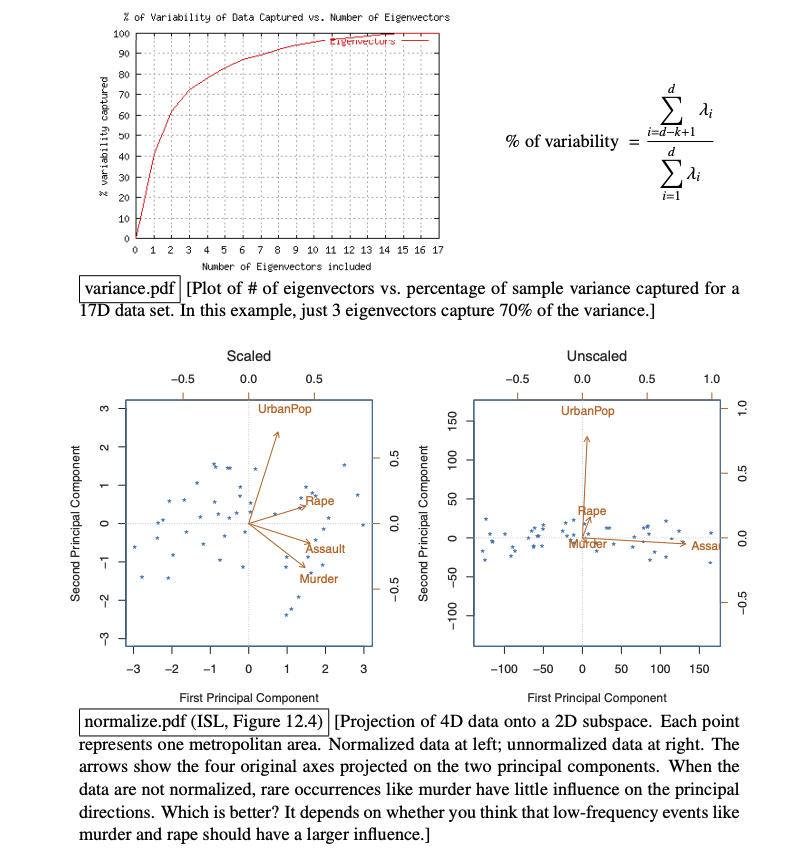
How to choose number of principal components and whether or not to normalize data before doing PCA.
Applications
- John Novembre: Genes mirror geography within Europe link
- EigenFaces (Face Recognition)
- Suppose we have
Xcontainsnimages of faces anddpixels each. - Face recognition: Given a query face, compare it with all training faces; find the nearest neighbor in .
- Runtime for each query:
- Solution: Run PCA on faces and project onto
d'subspaces where . - The new Runtime:
- If you have 500 stored faces with 40,000 pixels each, and you reduce them to 40 principal components, then each query face requires you to read 20,000 stored principal coordinates instead of 20 million pixels.
- Eigenfaces encode both face shape and lighting. Some people say that the first 3 eigenfaces are usually all about lighting, and you sometimes get better facial recognition by dropping the first 3 eigenfaces.
- Suppose we have
