Risk Minimization = Deriving the optimal classifier (r*)
Probabilistic Classifier - r
Risk - R
Risk(r) = Expected loss over all values of x and y for the specific classifier `r
Bayes decision rule = Bayes classifier = optimal probabilistic classifier
Posterior Probability Prior Probability
Decision Rule is called a classifier and is denoted by r. Formaljly,
Risk is denoted in capital R and is defined as the expected loss over all values of x and y
Loss Function
Loss function is generally in the form of , where is the predicted value by the classifier and y is the truth. Loss Function Value is always .
Risk Function
Risk is the expected loss over all values of x and y. Note that this is just a scalar value. Formally:
Rewriting this equation as parameterized by the input would be:
Thus,
Now that we know how to find the Risk, let’s explore the classifier called Bayes Decision, Bayes Classifier that minimizes this risk R(r). Assuming that , (which must hold true for all valid Loss functions):
The Optimal Classifier is defined as:
🔴 Note that LOSS FN x Probability = Expected Loss
So, we can interpret this as
The optimal classifer is one such that:
if the LOSS FN is symmetric:
pick the class with higher posterior probability
else:
weight the loss function value before the comparision
Example
Suppose 10% of population has cancer, 90% doesn’t.
P(Y = 1) = 0.1 P(Y = -1) = 0.9
The table below is so called likelihood, the probability of the observed evidence given a parameter value. This table is the probability distributions for occupation conditioned on cancer .
| job (X) | Miner | Farmer | Other |
|---|---|---|---|
| Cancer (Y = 1) | 20% | 50% | 30% |
| No Cancer (Y = -1) | 1% | 10% | 89% |
We want to calculate that - given a random person whom we only know their occupation, what is the chances that this person has cancer.
Everything above are a mixture of Posterior Probability and Prior Probability. Therefore, we calculate the posterior probability before anything.
Therefore, we calculate the evidence: P(X)
Now that we have the evidence, we can calculate the posterior probability:
Let’s define a LOSS FUNCTION for this example such that the false negative is considered worse than a false positive. Therefore,
Recall our Optimal Bayes Classifier:
If the stranger is Farmer for example, x = farmer
. Therefore, . Meaning the most optimized classifier will classify that every farmer has cancer.
🟡 However, remember that we have derived this equation so that we will need to do less computation. ^197f68 More specifically, we can calculate the Risk Value by only using the inputs:
Expected Loss for classifying Miner has NO Cancer: Expected Loss for classifying Miner has Cancer:
🔺 Main concept to understand Expected Loss for classifying Miner has NO Cancer > Expected Loss for classifying Miner has Cancer. So, a natural way to minimize the loss is to classify that every miner has cancer.
🔺An easier way to see this is, choose the truth value of Loss function of higher expected loss.
Loss Function :
Classifier’s loss for choosing 1 while the truth is -1
Bayes Classifier in simple words:
Suppose we have class 1 and class -1. If the expected loss for choosing -1 is higher than that of choosing 1, then the optimal solution is to choose class 1
Finishing up the example:
Expected Loss for classifying “Other” has Cancer:
Expected Loss for classifying “Other” don’t have Cancer: Thus,
Let’s also calculate the optimal Risk (Bayes Risk)
🔺 No decision rule gives a lower risk. Bayes risk is the lower bound.
🟩 Conclusion: Bayes Risk, R(r*) = 0.249 (Bayes Risk represents the minimum probability of the classifier getting it wrong overall)
Bayes Classifier for Continuous Distribution
Now that we understand the Bayes Classifier in Discrete Probability, we can now move to the continuous distributions.
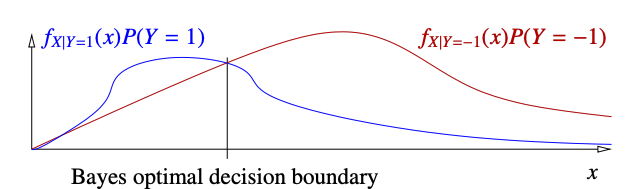
Suppose is the probability distribution of alcohol consumption given that the subject has cancer. So, naturally, means the probability distribution of alcohol consumption given that the subject does not have cancer.
We want to make a classifier that can classify whether the person has cancer or not based on the amount of alcohol consumption.
Also suppose we know that our prior probability are and .
Before we start, let’s define some definition first for the continuous distribution probability.
Risk of classifier “r” R(r) is defined as the expected loss over all x and y.
Parameterized with inputs: Prior probability, Likelihood and Loss Function
Note: The first term basically means expected loss for choosing class -1 and the second term is the expected loss for choosing class 1.
Thus, a Bayes Classifier will be:
If we have a symmetric loss function, 0-1 Loss function, the decision boundary / the classifier can be simplified to:
This simplification is due to the fact that
The Optimal Risk / Bayes Risk is
The good part - Looking at the distribution graphically. ( a lot easier )
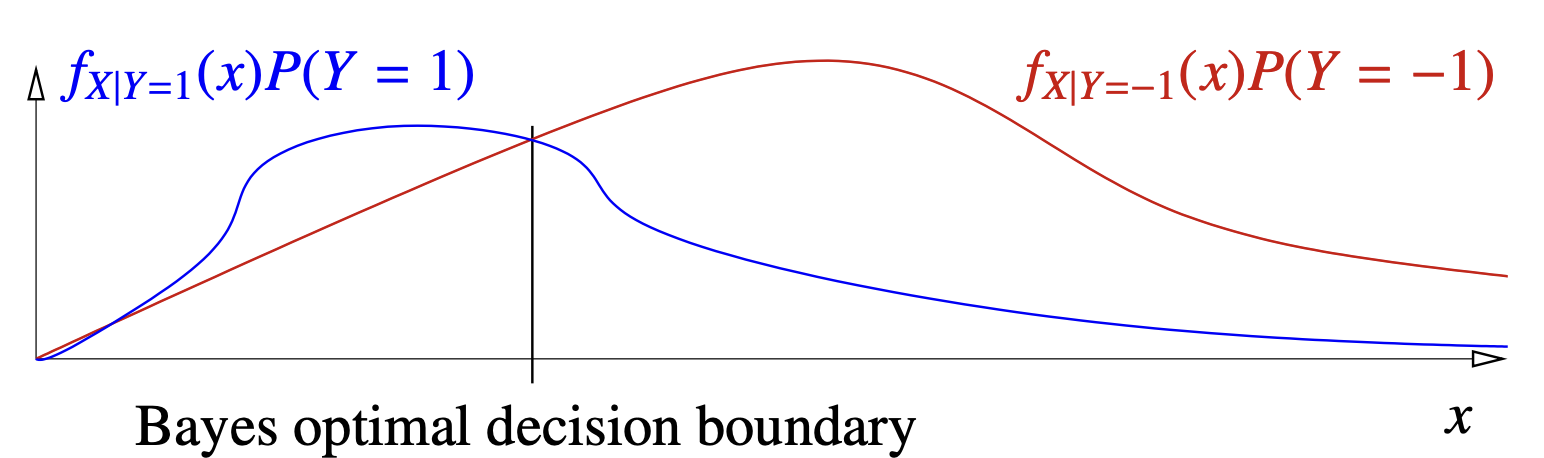
Decision Boundary:
In the above picture, we’re assuming that we have a 0-1 LOSS Function. Therefore, naturally, we can choose the one with higher posterior probability to reduce our risk. Recall that
This is similar to what the curves represent in the given picture except the denominator. But our goal is to compare the two posterior probabilities and thus we can just compare the given function directly without computing the Evidence
In the case of asymmetrical loss function, we can just scale the curves vertically in the figure above.
The intersecting section between the two curves is the decision boundary illustrated by a line.
Bayes Risk or Optimal Risk : the area under the minimum of functions given.
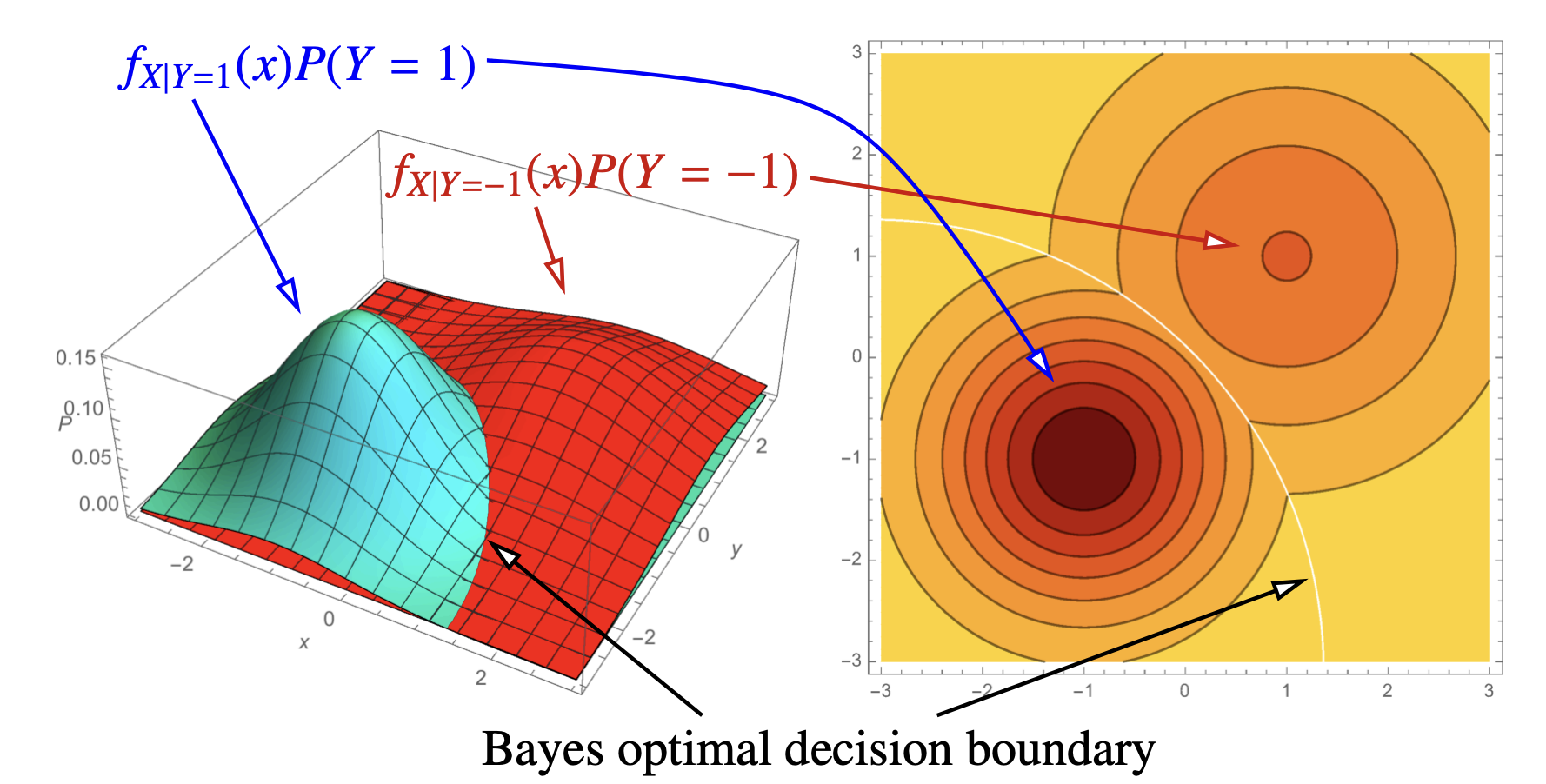
[[Building Classifiers]]