Preface
I will start this note with not much understanding of the models, but by the end of the note, I will revise the different models again, hopefully - with a better understanding of the concept.
3 Ways to Build Classifiers
- Generative Models (Linear Discriminant Analysis)
Core Idea: Try to learn the underlying probability distributions that generate the data for each class separately. Similar to figuring out how “each class” creates its data points.
- Discriminative Models (Logistic Regression)
This model Directly Learn the Decision Boundary between classes or the conditional probability without explicitly modeling the individual class distributions. “The Focus is on Finding WHAT separates the classes from each other .”
- Find Decision Boundary (Support Vector Machine)
No explicit calculations of Probabilities. Directly find the Optimal Decision Boundary that separates the classes.
⭕ Come back to recognize the advantages and disadvantages of different models.
Gaussian Discriminant Analysis
Caution: Although the name is called Gaussian “Discriminant” Analysis, please note that this model is a generative model. The key factor is “How it Learns”. The overall technique is:
- Assume Gaussian Distributions for each class.
- Estimate the parameters (mean and covariance) of these distributions. (Maximum Likelihood Estimation)
- Use Bayes’ theorem to get , the probability of the class given features.
First modeling the probability distribution of each class separately. And learns The probability of observing features given a class (Hallmark of a generative model). Model .
Fundamental Assumption: Each class has a Normal Gaussian Distribution.
How did we get here?
How did we get this Multivariate Gaussian Distribution with a scalar instead of a covariance matrix ?
For each class C, SUPPOSE we know and variance which gives us the PDF and we know prior probability .
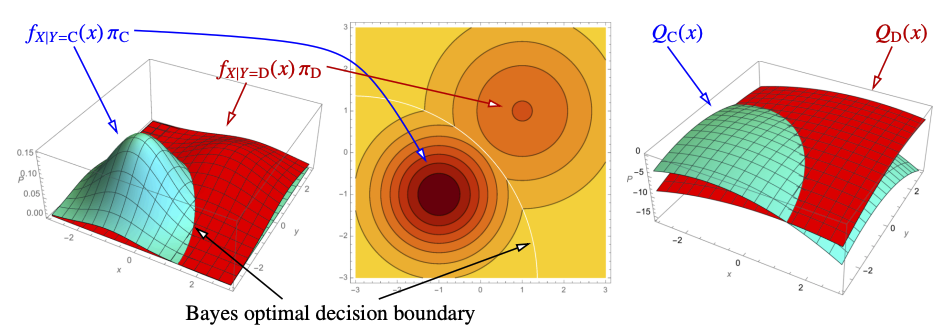
🚨 In this example, we are assuming that the variance is a scalar, which results in circular iso-contours and not ellipses. This is called isotropic normal distribution because the variance is the same in all directions. Anisotropic Gaussians = isosurfaces are ellipsoids. Also, the Bayes Decision boundary is an ellipse.
From Decision Theory, we know that the optimal classifier should pick the particular class C such that it maximizes the expected loss :
Since we’re considering 0-1 Loss Function, we can also recall the main principle : Pick the class with the highest Posterior Probability
For the sake of simplifying the Math - Maximizing is the same as maximizing . The term is just to cancel out the term in the Gaussian Distribution ^f1b0fd.
Therefore,
🔺 Notice that is a quadratic function.
In a 2-class problem, we can also add asymmetric loss function by adding . In a multi-class though, it will be more harder to account for the loss function.
Quadratic Discriminant Analysis (QDA)
Suppose we only have two classes C and D. Then, by Bayes Theorem:
Bayes Deicions Boundary is where x satisfies
is a quadratic function and therefore, in 1-dimension, the BDB may have 1 or 2 points. In d-dimension, the BDB is a quadric
🔴 Q: What about the probability that our prediction is correct? This is basically the same as
By the law of total probability:
Substitute equation ^25d885,
Definition
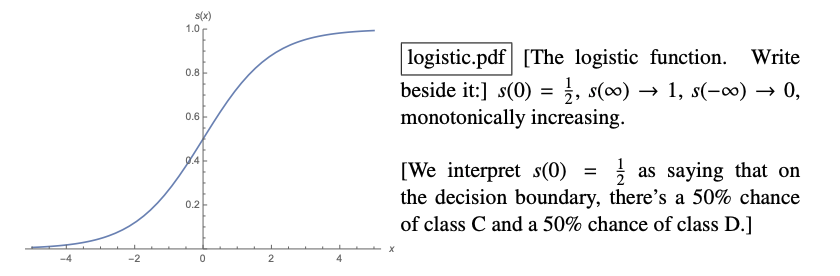
Logistic Function / Sigmoid Function (Real-valued input Probability) is in the form of :
Putting our probability equation into sigmoid function (monotonically increasing) form:
🔴 Answer: Now, we can calculate our correctness of the prediction using the sigmoid function.
Recall the decision function is . The output of the sigmoid function can be interpreted as the probability of the data point belonging to the correct class.
Multi-Class Quadratic Discriminant Analysis (QDA) is quite natural. “multiple decision boundaries that adjoin each other at joints.” The way we do this is by calculating of each class and choose the maximum.

Notice the variance and the boundary
- The dots are the means of each class, and the variances are the circular shapes in the graph. The circular shapes are not spread out equally across different classes, which means that they have different variances.
- Also notice that the decision boundary are not linear since our are quadratic functions. come back for updates! Ed Thread
Linear Discriminant Analysis (LDA)
Now that we know QDA, let’s explore what happens IF all the Gaussians have the same variance .
QDA allows each class to have its own covariance matrix where k is a class. LDA is a variant of QDA with Linear Decision Boundaries, where all classes have same covariance matrix .
LDA is also less likely to overfit since we assume the same covariance matrix (variance) for all class, reducing the number of parameters to estimate.
Recall that we defined Q(x) to be a natural log of the Gaussian PDF: ^25d885
But, we had made an important assumption in LDA that all are the same. Therefore, the decision boundary is simplified to:
Now, the decision boundary equation is evidently in the familiar linear form of as the quadratic terms in and cancel out each other.
Similar to what we did in QDA, we can find the correctness probability of our prediction (a.k.a) the posterior probability in the case of 0-1 Loss Function.
To emphasize the linearity, we can rewrite this as:
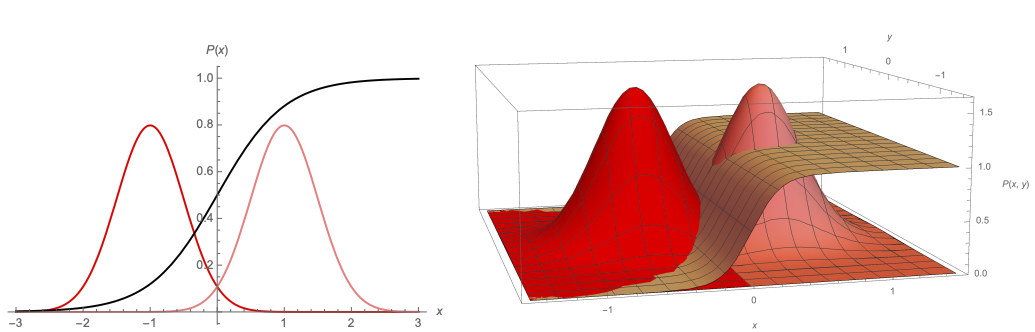
If is the right Gaussian, the logistic (sigmoid) function is the right Gaussian divided by the sum of two Gaussians. 🔺 Another observation is that the logistic function look 1D even though the Gaussians are 2D. In Higher Dimensions, the logistic function is essentially varying in only one direction and unchanging in all other directions.
A Side Note: In Logistic Regression, we are assuming that the posterior probability is in the “sigmoid form” and don’t care about the underlying class conditional PDFs.
Centroid Method → Special Case of GDA: Same Prior Probability and Same Variance for all classes.
Class C and Class D have same variance as well as the same Prior Probability
Then, the Bayes decision boundary is :
This equation is the same as the “centroid method”.
Multi-Class LDA: choose C that maximizes the Linear Discriminant Function
When we have Classes with Same Variance and Same Prior Probabilities, the decision boundary diagram becomes a Voronoi Diagram.
If we only have Same Variance but different Prior Probabilities, the decision boundary diagram becomes a Power Diagram.

Voronoi Diagram : A Voronoi diagram divides a space into regions where each region corresponds to a "generator" point. Every location within a region is closer to its corresponding generator than to any other generator. Power Diagram: A power diagram, also known as a weighted Voronoi diagram, generalizes the concept of a Voronoi diagram by assigning a weight to each generator point. The distance metric is modified to account for these weights, leading to regions defined by the "power distance" rather than the standard Euclidean distance.