The pdf of X is
where, .
is the d x d PSD Covariance Matrix is the d x d PSD Precision Matrix
For understanding the function easier, rewrite where .
If we think carefully, we notice that is a , and is a .
is a quadratic function that we know. is the quadratic form of the precision matrix (a quadratic bowl with center at ). is a monotonic, convex function: an exponential of the negation of the half of its argument. The graphs are shown below.
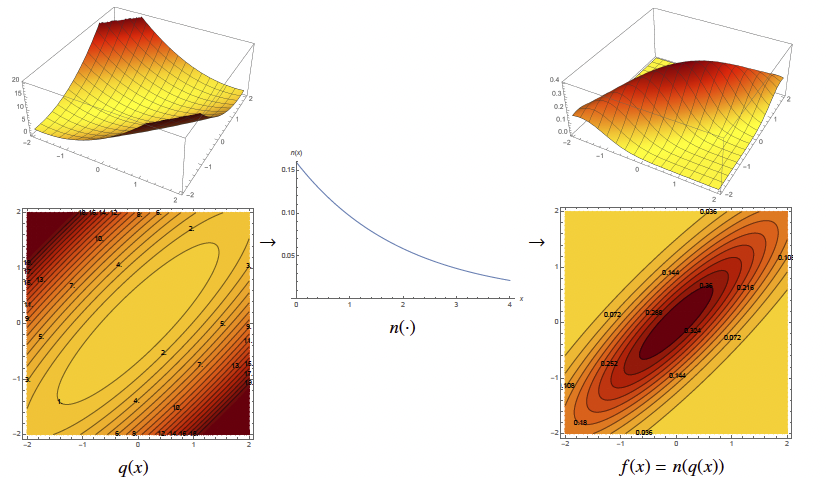
The two graphs have different isovalues, but the mapping doesn’t change its isosurfaces. Thus, minimization of q(x) is equivalent to the maximization of the probability distribution function.
Hint
Meaning of “Different isovalues but same isosurfaces”: This suggests that the contour levels (isovalues) of the function change, but the overall structure of the level sets (isosurfaces) remains the same. This typically happens when you apply a monotonic transformation to a function. In our case, this function is exponential function.
Summary
If you understand the isosurfaces of a quadratic function, then you understand the isosurfaces of a Gaussian, because they’re the same.
Remember from Visualizing Quadratic Form that the isocontours of are determined by the eigenvalues and eigenvectors of .
Side Notes
Remember from the induced norm theorem that, is some sort of norm squared. In this case, having a precision matrix in the middle means that the norm is a sort of warped distance from x to mean . Formally:
Shewchuk
So we think of the precision matrix as a “metric tensor” which defines a metric, a sort of warped distance from x to the mean μ.