4.1 code Implement Decision Trees
4.2 code Implement a Random Forest
4.3
4.3.1. Categorical features are transformed into one-hot encoding and missing values are filled with the mode of that column. 4.3.2 max_depth reach or if the node only contains same labels. 4.3.3 By using bagged decision tree. and setting a parameter m, which defines how many features out of total features will be used for each decision tree in the forest. 4.3.4 No 4.3.5 Feature engineering. Cumulate similar data features and add it as a new feature.
4.4
Decision Tree Accuracies for Spam
- Training Accuracy: 0.8162919990331158
- Validation Accuracy: 0.8057971014492754 Random Forests Accuracies for Spam
- Training Accuracy: 0.8399806623156877
- Validation Accuracy: 0.8222222222222222
- Cross validation [0.82995169 0.83671498 0.83752418 0.81237911 0.80560928]
Decision Tree Accuracies for Titanic
- Training Accuracy: 0.8397997496871089
- Validation Accuracy: 0.795 Random Forests Accuracies for Titanic
- Training Accuracy: 0.8197747183979975
- Validation Accuracy: 0.8
- Cross validation [0.785 0.82 0.765 0.835 0.79899497]
Kaggle Submissions
- Kaggle Display Name: williamkan
- Titanic Public Score: 0.838
- Spam Public Score: 0.808


4.5
4.5.1 Decision path for a ham email:
- exclamation < 0.50
- meter < 0.50
- parenthesis < 0.50
- Leaf: 0 (Therefore this email was ham)
Decision path for a spam email:
- exclamation >= 0.50
- ampersand < 0.50
- meter < 0.50
- Leaf: 1 (Therefore this email was spam)
4.5.2
Depth with highest validation accuracy: 19
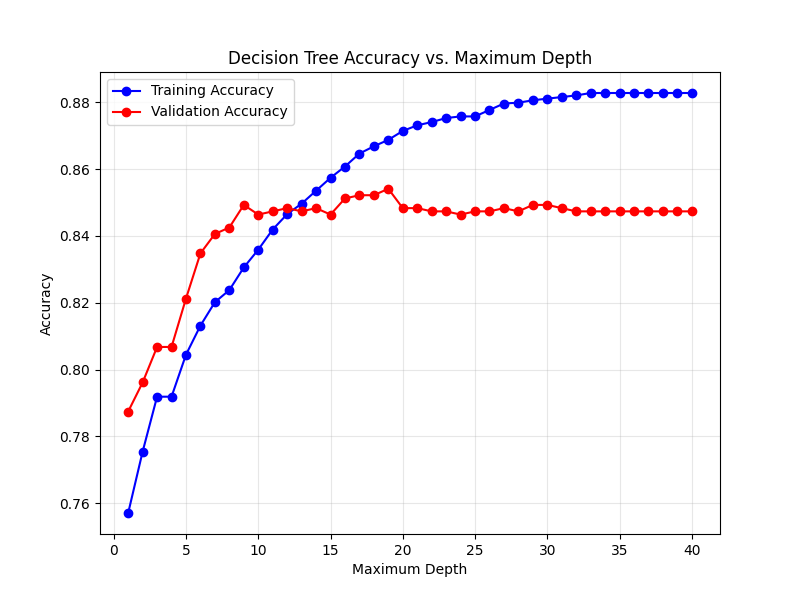
The validation accuracy increases with the tree depth until a maximum is reached at depth 19. The training accuracy continues to increase as the depth increases, indicating the significance of overfitting. We can conclude that the decision tree with 19 as maximum depth can capture the underlying pattern without overfitting.